1. NTILE() 함수
: NTILE() 함수는 계산 대상 데이타(ROW) 들을 특정한 기준으로 분할하여 그 결과값을 반환하는 분석함수.
구문형식
|
NTILE(EXPR) OVER(PARTITION BY EXPR1 ORDER BY EXPR2 [ASC|DESC]) |
예1) NTILE(5) OVER(ORDER BY SUM(ORDER_DETAIL) DESC) 라면
RESULTSET 을,또는 RESULTSET 의 갯수를 5등분 하고 SUM(ORDER_DETAIL) DESC 순으로 정렬한다는 것. 5등분할 때 각 레코드들에 1부터 5까지 번호를 순차적으로 붙인다.
예2) 아래 예는 데이타가 없음. 그냥 쿼리만 볼 것.
다음은 99년도 주문에서 상위 20%의 고객이 누구인지 알아보는 쿼리
--전체 RESULTSET 중 20%만 보고 싶다면 전체 RESULTSET 을 5등분 한 후 아래 RANK 알리아스에 1이 들어가 있는 것들만 뽑아내면 된다.
SELECT CUSTOMER_ID,
--PARTITION BY 절이 없으니 아래는 모든 RESULTSET 을 5등분 할 것.
NTILE(5) OVER(PARTITION BY SUM(ORDER_TOTAL) DESC) RANK,
SUM(ORDER_TOTAL)
FROM ORDERS
WHERE TO_CHAR(ORDER_DATE,'YYYY') = 1999'
GROUP BY CUSTOMER_ID;
예3) SCOTT/TIGER 로 로그인한다.
SELECT T.*,
NTILE(3) OVER(ORDER BY HIREDATE) RANK
FROM EMP T;
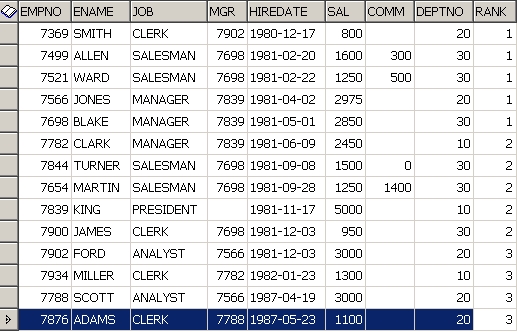
위를 실행하면 전체 14개의 RESULTSET 을 3개로 나눠서 RANK 라는 필드에 ORDER BY HIREDATE 으로 정렬된 상태에서 위에서부터 1,2,3 을 붙인다. 아래처럼 1이 5개, 2가 5개, 3이 4개가 나옴.
* NTILE 에서 나머지가 생기는 경우가 있다. 이 때는 번호가 아래와 같이 배분된다.
예를 들어 NTILE(4) 를 사용하면, 각 ROW를 순서대로 25%씩 나누어 1부터 4의 숫자를 리턴해 준다.
그런데 전체 RESULTSET 이 103개인경우라면 어떻게 될까?
정확히 25%로 나누면 나머지가 생기게 되는데, 103/4 로 나누고 나서 남은 나머지는 3이고 , 이건 맨 뒤에 5라는 숫자를 붙이는게 아니라, 최초 값부터 1개씩 추가로 분배하게 된다. 그러니까 전체 RESULTSET 이 103개 인데, NTILE(4) 를 쓰면 상위 26개의 ROW 가 1, 그 다음 26개가 2, 그 다음 26개가 4, 그 나머지 25개의 로우는 4를 반환하게 된다.
아래를 실행해 보면
SELECT T.*,
NTILE(4) OVER(ORDER BY HIREDATE) RANK
FROM EMP T;
NTILE(4) 이므로 일단, 4보다 큰 숫자는 배분될 수 없다. 전체 14개 RESULTSET 을 4로 나누면 2가 남으니 각 하나씩 최상위 1부터 2에 각각 하나씩 배분되고 아래와 같은 모양이 된다.
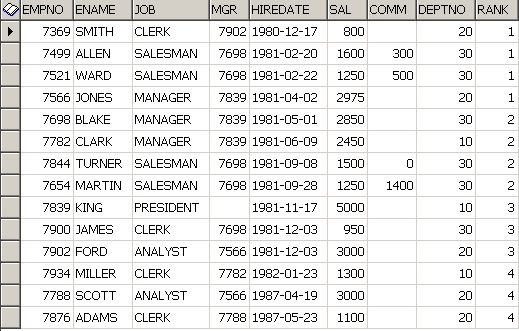
결국 1이 4개, 2가 4개, 3이 3개, 4가 3개가 된다.
2. RATIO_TO_REPORT 함수
구문형식
|
RATIO_TO_REPORT (EXPR) OVER (PARTITION BY 절) |
RATIO_TO_REPORT 함수는 계산 대상 값 전체에 대한 현재 ROW 의 상대적인 비율값을 반환하는 함수임.
RATIO_TO_REPORT 함수는 계산 대상 데이터(ROW들)들을 PARTITION BY 로 구분하여 EXPR 에 명시된값의 전체 합계에 대한 각각의 ROW 의 상대적인 값을 반환한다. 만약 EXPR 값으로 NULL 이 명시되면 반환값 역시 NULL 이다.
간단하게 말하면 A 라는 필드가 있을 때 'RATIO_TO_REPORT(A)' 로 하기만 하면, SUM(A) 한 것을 기준으로 A 가 SUM(A)에서 몇 % 나 차지하는지 A/SUM(A) 로 각각의 ROW 마다 계산하여 리턴해 주는 함수임.
A가 SUM(SUM(필드명)) 이라면 RATIO_TO_REPORT 함수는
SUM(SUM(필드명))/SUM(SUM(SUM(필드명))) 의 값을 리턴해 주는 것.
A 부분은 얼마든지 더 복잡해 질 수 있음.
* 아래는 RATIO_TO_REPORT 함수 예제.
-- DANIEL 로 로그인 하여 아래 쿼리 날려본다. 5월 한 달간 각 아이템별 판매액이 날짜별로 나온다.
SELECT *
FROM SALE_HIST
ORDER BY SALE_DATE , SALE_ITEM
결과는 아래와 같다.
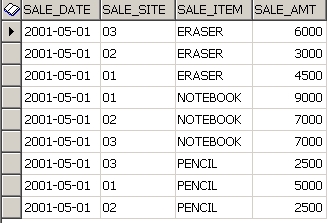
이 테이블에서 각 아이템의 날짜별 판매비율을 구해야 한다고 가정하면.
우선 아래와 같은 쿼리로 각 아이템의 날짜별 판매액 합계를 구한다.
SELECT SALE_DATE, SUM(SALE_AMT) , SALE_ITEM
FROM SALE_HIST
GROUP BY SALE_DATE , SALE_ITEM
ORDER BY SALE_DATE , SALE_ITEM
위 쿼리의 결과는 아래와 같다.
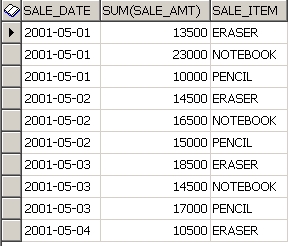
이제 아래 쿼리로 각 아이템의 날짜별 판매비율을 구하면 된다.
SELECT SALE_DATE, SUM(SALE_AMT) , SALE_ITEM ,
--아래 분석 함수는 괄호의 위치가 조금 틀리거나 괄호 갯수가 하나만 틀려도
-- ORA-30483: 윈도우 함수를 여기에 사용할 수 없습니다 라는 오류 메시지 뜬다.
ROUND(SUM(SALE_AMT)/SUM(SUM(SALE_AMT)) OVER(PARTITION BY SALE_ITEM),2) RATIO
FROM SALE_HIST
GROUP BY SALE_DATE , SALE_ITEM
ORDER BY SALE_ITEM , SALE_DATE
** 위 쿼리를 RATIO_TO_REPORT 함수를 써서 고치면 아래와 같이 된다.
SELECT SALE_DATE, SUM(SALE_AMT) , SALE_ITEM ,
RATIO_TO_REPORT (SUM(SALE_AMT)) OVER (PARTITION BY SALE_ITEM ) RATIO
FROM SALE_HIST
GROUP BY SALE_DATE , SALE_ITEM
ORDER BY SALE_ITEM , SALE_DATE
위 SUM(SALE_AMT)/SUM(SUM(SALE_AMT)) 부분이 --> RATIO_TO_REPORT (SUM(SALE_AMT)) 로 변경되었음.
위의 쿼리를 돌려보면 아래와 같이 나옴.
비교를 위해 RATIO_TO_REPORT 함수 쓴 쿼리는 ROUND 함수를 쓰지 않았음.
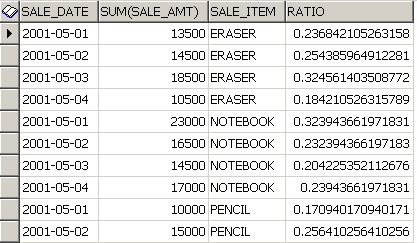
결국, RATIO_TO_REPORT 함수는 PARTITION BY 절에 명시된 그룹의
SUM(SALE_AMT) 값의 전체 합계(SUM(SUM(SALE_AMT)))에서의 비율을 리턴해 주는 함수임.
* 위와 동일한 테이블에서 다른 예제.
- 특정 월(01년 05월)에 어떤 판매처(SALE_SITE 필드)에서 어떤 아이템(SALE_ITEM) 이 어느정도 팔렸는지 알고 싶다면?
먼저, 판매처별 , 아이템별 판매 현황을 보기위해 아래 쿼리를 실행시킨다.
SELECT *
FROM SALE_HIST
WHERE SUBSTR(TO_CHAR(SALE_DATE,'YYYYMMDD'),1,6) = '200105'
ORDER BY SALE_SITE , SALE_ITEM
결과는 아래와 같다.
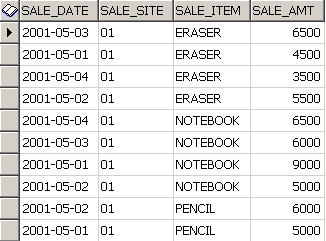
--지우개가 어느 판매점에서 몇 % 팔렸는지등을 알아내는게 목표니까
-- 분석함수 쓰기 전에 먼저 아이템과 판매점으로 group by 해서
-- 아이템 별로 어떤 판매점에서 총 얼마나 판매 되었는지 확인한다.
SELECT SALE_ITEM ,SALE_SITE, SUM(SALE_AMT)
FROM SALE_HIST
WHERE SUBSTR(TO_CHAR(SALE_DATE,'YYYYMMDD'),1,6) = '200105'
GROUP BY SALE_ITEM, SALE_SITE
ORDER BY SALE_ITEM, SALE_SITE
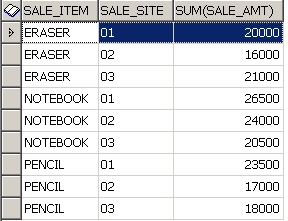
이제 마지막으로 분석함수를 집어 넣는다.
RATIO_TO_REPORT(A) 의 형식에 집어 넣으면 됨. A 는 위에서 SUM(SALE_AMT) 임.
아래처럼 쿼리를 만들면 됨.
--각 판매점에서 각 아이템별로 어느 정도 많이 판매 되었는지를
-- 확인해야 하므로 아이템별로 그룹핑 시켜야 한다 PARTITION BY 는 아이템으로 해야 한다는 말.
-- 그리고 각 ROW 를 돌면서 해당 ROW 의 SUM(SALE_AMT) 가 그 아이템의 전체 판매량 에서
-- 어느 정도의 비중을 차지하는지 RATIO_TO_REPORT 에게 구하라고 한다.
-- 아래 쿼리와 같이 구한다.
SELECT SALE_ITEM ,SALE_SITE, SUM(SALE_AMT) ,
ROUND(RATIO_TO_REPORT(SUM(SALE_AMT)) OVER(PARTITION BY SALE_ITEM),2) RATIO
FROM SALE_HIST
WHERE SUBSTR(TO_CHAR(SALE_DATE,'YYYYMMDD'),1,6) = '200105'
GROUP BY SALE_ITEM, SALE_SITE
ORDER BY SALE_ITEM, SALE_SITE
위 쿼리를 실행하면 다음과 같다.
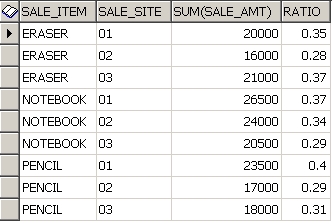
지우개의 경우 1번 판매점에서 5월 판매량의 35% 판매했다는 얘기.......등등.
3. WIDTH_BUCKET 함수
: WIDTH_BUCKET 함수 역시 특정 기준에 의해 RESULTSET 에 번호를 부여하는 함수다. NTILE 과 분할하여 번호 붙이는 기준만 다를 뿐임.
구문형식
|
WIDTH_BUCKET (EXPR, MIN_VALUE, MAX_VALUE, NUM_BUCKETS) |
WIDTH_BUCKET 함수는 EXPR 에 명시된 값들을 대상으로,
MIN_VALUE 와 MAX_VALUE 사이를 NUM_BUCKETS 만큼 분할하여 각각의 ROW 에 1번부터 번호를 붙인다.
테스트를 위해 아래 스크립트로 테이블을 만들고 데이타를 넣는다.
CREATE TABLE STAT_TEST (
T_VALUE NUMBER );
INSERT INTO STAT_TEST VALUES(10);
INSERT INTO STAT_TEST VALUES(35);
INSERT INTO STAT_TEST VALUES(26);
INSERT INTO STAT_TEST VALUES(55);
INSERT INTO STAT_TEST VALUES(49);
INSERT INTO STAT_TEST VALUES(75);
INSERT INTO STAT_TEST VALUES(9);
INSERT INTO STAT_TEST VALUES(29);
INSERT INTO STAT_TEST VALUES(44);
INSERT INTO STAT_TEST VALUES(99);
예를 들어보면,
WIDTH_BUCKET(T_VALUE, 1 ,100 ,4 ) 는 T_VALUE 들의 ROW 들에 대해서 각각 번호를 부여하되,
어떤 번호를 어디에 부여하냐면, 1 부터 100 까지 4등분을 한 후 T_VALUE 에 있는 번호를 보고 적당한 번호를 붙여라..라는 얘기.
그러니까 1부터 100을 4등분하면 1~25, 26~50, 51~75, 76~100 이니까
T_VALUE 가 1~25 면 1을 부여하고,
T_VALUE 가 26~50 면 2를 부여하고,
T_VALUE 가 51~75 면 3을 부여하고,
T_VALUE 가 76~100 면 4를 부여하라는 것.
테스트로 아래처럼 쿼리를 날려본다.
SELECT T_VALUE,
WIDTH_BUCKET(T_VALUE, 1 ,100 ,4 ) WIDTH
FROM STAT_TEST
ORDER BY WIDTH
결과는 아래와 같다.
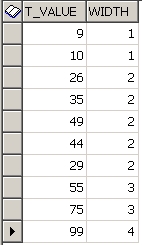
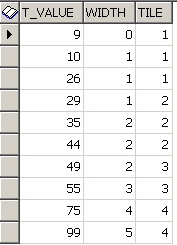
위에 나오듯이, 9는 1~25 사이니까 1을 부여, 10도 1~25사이니까 1을 부여, ..... 75 는 51~75 사이니까 3을 부여.... 와 같은 식으로 되는 것임.
만약 WIDTH_BUCKET(T_VALUE, 1 ,100 ,4 ) 와 같은 식에서 T_VALUE 의 값이 최소값인 1보다 작으면 무조건 0 을 리턴하고 최대값인 100보다 크면 맨 마지막 매변의 숫자 + 1 한 값을 리턴한다.
WIDTH_BUCKET(T_VALUE, 1 ,100 ,4 ) 의 경우 T_VALUE 값이 130 이라면 마지막 매변인 4+1 을 해서 5를 리턴하게 되는 것.
* 아래 쿼리로 NTILE 과 WIDTH_BUCKET 함수를 비교해 볼 것.
SELECT T_VALUE,
WIDTH_BUCKET(T_VALUE,10, 90 ,4) WIDTH,
NTILE(4) OVER(ORDER BY T_VALUE) TILE
FROM STAT_TEST
ORDER BY T_VALUE
결과는 아래와 같다.